OS Note Chapter 5: CPU Scheduling
Basic Concepts
- Purpose of multiprogramming: maximum CPU utilization
CPU–I/O Burst Cycle
- Process execution consists of a cycle of CPU execution and I/O wait
- CPU burst followed by I/O burst
- CPU burst distribution is of main concern:
- a large number of short CPU bursts and
- a small number of long CPU bursts.
- CPU burst distribution is of main concern:
| Operation | Type |
|---|---|
| Load store, add store, read from file | CPU burst |
| Wait for I/O | I/O burst |
| Store increment index, write to file | CPU burst |
| Wait for I/O | I/O burst |
| Load store, add store, read from file | CPU burst |
| Wait for I/O | I/O burst |
| …… | …… |
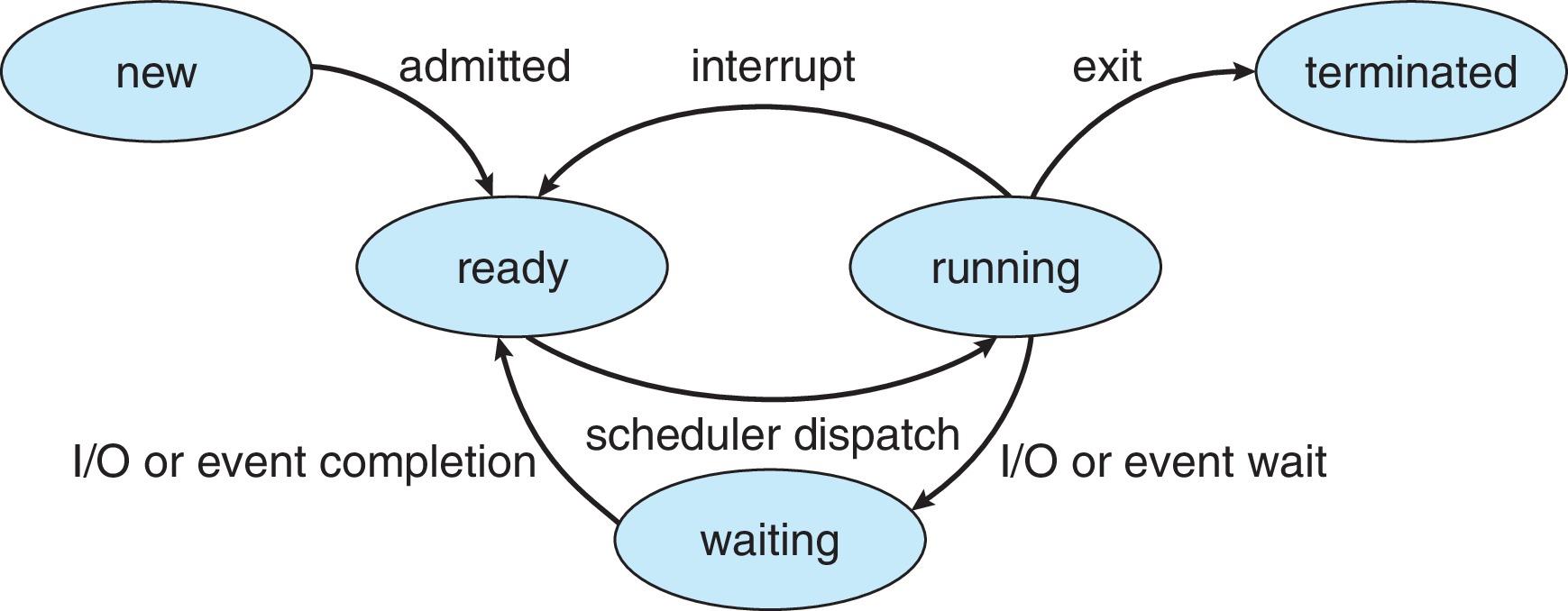
Process State Transition
CPU Scheduler
-
The CPU scheduler (CPU 调度程序) selects a process from the processes in ready queue, and allocates the CPU to it
- Ready queue may be ordered in various ways
-
CPU scheduling decisions may take place when a process
- switches from running to waiting state (non-preemptive 自愿 离开CPU)
- Example: the process does an I/O system call.
- switches from running to ready state (preemptive 强占)
- Example: there is a clock interrupt.
- switches from waiting to ready (preemptive)
- Example: there is a hard disk controller interrupt because the I/O is finished.
- terminates (non-preemptive 自愿离开CPU)
- switches from running to waiting state (non-preemptive 自愿 离开CPU)
-
Scheduling under 1 and 4 is non-preemptive (非强占的, decided by the process itself)
-
All other scheduling is pre-emptive (强占的, decided by the hardware and kernel)
-
Preemptive scheduling can result in race conditions (will introduced in chapter 6) when data are shared among several processes
-
Some considerations in pre-emptive scheduling
- Access to shared data
- Preemption issue while CPU is in kernel mode
- How to handle interrupts during crucial OS activities
-
Preemptive vs. Nonpreemptive Scheduling
-
When a process is pre-empted,
- It is moved from its current processor
- However, it still remains in memory and in ready queue
-
Why preemptive scheduling is used?
- Improve response times
- Create interactive environments (real-time)
-
Non-preemptive scheduling
- Process runs until completion or until they yield control of a processor
-
Disadvantage
- Unimportant processes can block important ones indefinitely
-
Scheduling Criteria
Maximize
- CPU utilization – keep the CPU as busy as possible
- Throughput – number of processes that complete their execution per time unit
- Increase throughput as high as possible
Minimize
- Response time – amount of time it takes from when a request was submitted until the first response is produced, not output (for time-sharing environment)
- Waiting time – total amount of time a process has been waiting in the ready queue
Other
- Turnaround time – amount of time to execute a particular process (from start to end of process, including waiting time)
- Turnaround time = Waiting time + time for all CPU bursts
Scheduling Algorithms
- First-Come, First-Served (FCFS)
- Shortest-Job-First (SJF)
- Priority Scheduling (PS)
- Round-Robin (RR)
- Multilevel Queue Scheduling (MQS)
- Multilevel Feedback Queue Scheduling (MFQS)
First-Come, First-Served (FCFS) Scheduling
-
Suppose that the processes arrive in the ready queue at time $t = 0$ in the following order: $P_1$ , $P_2$ , $P_3$
-
Burst time for each process is
Process Burst Time $P_1$ 24 $P_2$ 3 $P_3$ 3 The Gantt Chart for the schedule is:

-
Waiting time: $P_1=0$; $P_2=24$; $P_3=27$.
- Average waiting time: $(0 + 24 + 27) / 3 = 17$
- Average turnaround time: $(24+27+30)/3 = 27$
-
Suppose the order is changed to this: $P_2$ , $P_3$ , $P_1$
-
The Gantt chart for the schedule is then:

- Waiting time: $P_1=6$; $P_2=0$; $P_3=3$.
- Average waiting time: $(6 + 0 + 3) / 3 = 3$
- Average turnaround time: $(30+3+6)/3 = 13$
- Much better than previous case
- Convoy effect(护送效应) - short process behind long process
- Consider one CPU-bound (long CPU burst, short I/O burst) and many I/O-bound (long I/O burst, short CPU burst) processes
Shortest-Job-First (SJF) Scheduling
- Associate with each process the length of its next CPU burst
- Use these lengths to schedule the process with the shortest time
- SJF is optimal – gives minimum average waiting time for a given set of processes
- The difficulty is knowing the length of the next CPU request
- Could ask the user
| Process | Arrival Time | Burst Time |
|---|---|---|
| $P_1$ | 0 | 6 |
| $P_2$ | 2 | 8 |
| $P_3$ | 4 | 7 |
| $P_4$ | 5 | 3 |
- SJF scheduling chart

- Average waiting time = $(3 + 16 + 9 + 0) / 4 = 7$
- Average turnaround time = $(9+24+16+3)/4 = 13$
Shortest-remaining-time-first
Determining Length of Next CPU Burst
- Actually the length of next CPU burst can only be estimated
- Next burst length should be similar to the previous one (use the past to predict the future).
- Then pick process with shortest predicted next CPU burst
- Use the length of previous CPU bursts, with exponential averaging
- $t_n=actual\ length\ of\ n^{th}\ CPU\ burst$
- $\tau_{n+1} = predicted\ value\ for\ the\ next\ CPU\ burst$
- $\alpha, 0\leq\alpha\leq1$ (commonly, $\alpha$ set to $\frac{1}{2}$)
- Define: $\tau_{n+1}=\alpha t_𝑛+(1−\alpha)\tau_n$
- The preemptive version of SJF is also called shortest-remaining-time-first
- $\tau_{n+1}=\alpha t_𝑛+(1−\alpha)\tau_n=\frac{1}{2}(t_n+\tau_n)$
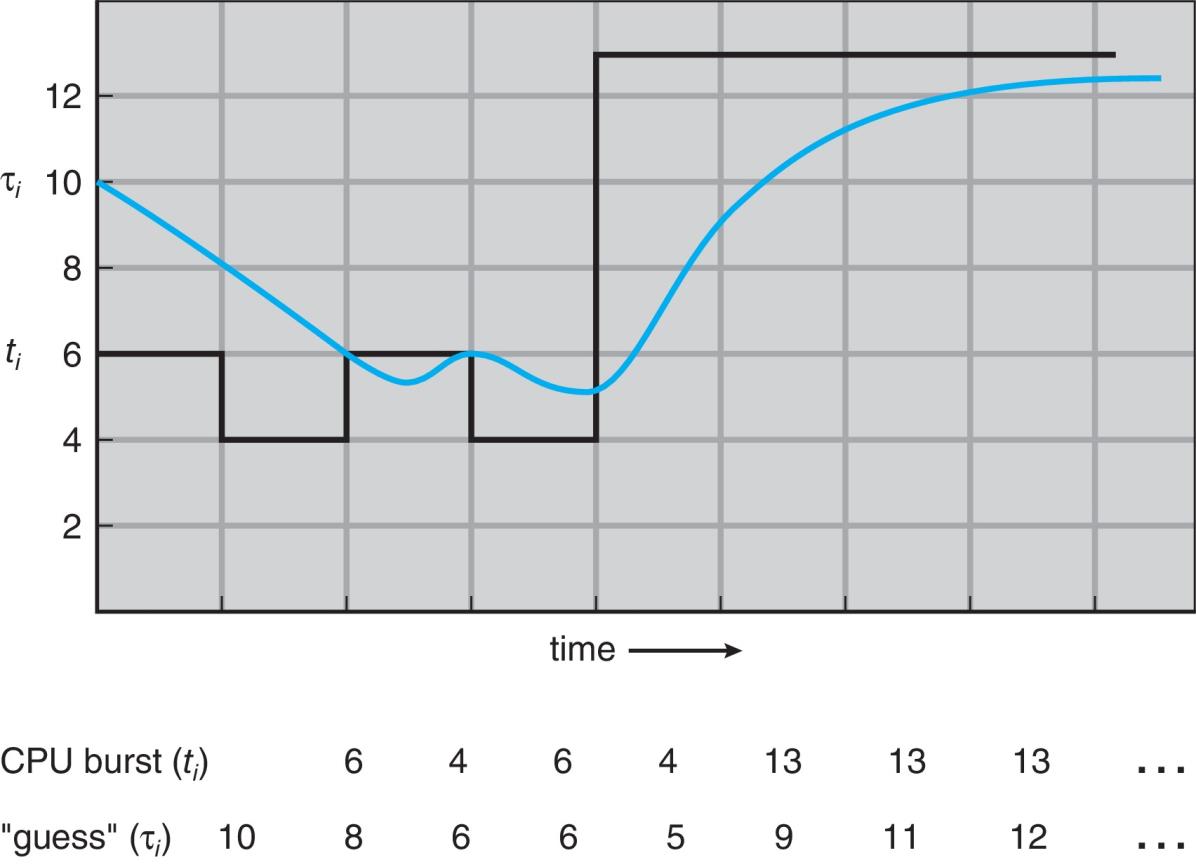
Examples of Exponential Averaging
- $\alpha=0$
- $\tau_{n+1}=\tau_n=…=\tau_0$
- History does not count: always use the same guess regardless of what the process actually does.
- $\alpha=1$
- $\tau_{n+1}=t_n$
- Only the actual last CPU burst counts
- In general, if we expand the formula, we get:
- $\tau_{n+1} = \alpha t_n+(1 - \alpha)\alpha t_{n -1} + … $ $(1 - \alpha)^j \alpha t_{n-j}+…$ $+(1 - \alpha)^{n+1} \tau_0$
- Since both $\alpha$ and $(1 - \alpha)$ are less than or equal to 1, each successive term has less weight than its predecessor
Example of Shortest-remaining-time-first
- Now we add the concepts of varying arrival times and preemption to the analysis
| Process | Arrival Time | Burst Time |
|---|---|---|
| $P_1$ | 0 | 8 |
| $P_2$ | 1 | 4 |
| $P_3$ | 2 | 9 |
| $P_4$ | 3 | 5 |
- Preemptive SJF (shortest-remaining-time-first) Gantt Chart

- Average waiting time = [(10-1)+(1-1)+(17-2)+(5-3)] / 4 = 26 / 4 = 6.5
- Average turnaround time = (17+4+24+7)/4 = 13
Round Robin (RR)
-
Each process gets a small unit of CPU time (time quantum 定额 $q$), usually 10-100 milliseconds.
-
After $q$ has elapsed, the process is preempted by a clock interrupt and added to the end of the ready queue.
- Timer interrupts every quantum $q$ to schedule next process
-
If there are $n$ processes in the ready queue and the time quantum is $q$. No process waits more than $(n-1)*q$.
-
Performance
- $q$ too large => FCFS
- $q$ too small => too much time is spent on context switch
- $q$ should be large compared to context switch time
- $q$ usually 10ms to 100ms, context switch < 10 usec (微秒)
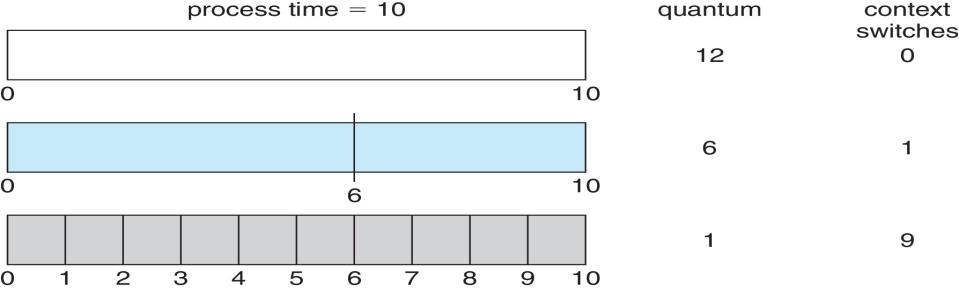
Example of RR with Time Quantum = 4
| Process | Burst Time |
|---|---|
| $P_1$ | 24 |
| $P_2$ | 3 |
| $P_3$ | 3 |
- The Gantt Chart is:

- Typically, higher average turnaround than SJF, but better response
- Average waiting time = $(6+4+7)/3 = 5.67$
- Average turnaround time = $(30+7+10)/3 = 15.7$
Turnaround Time Varies With The Time Quantum
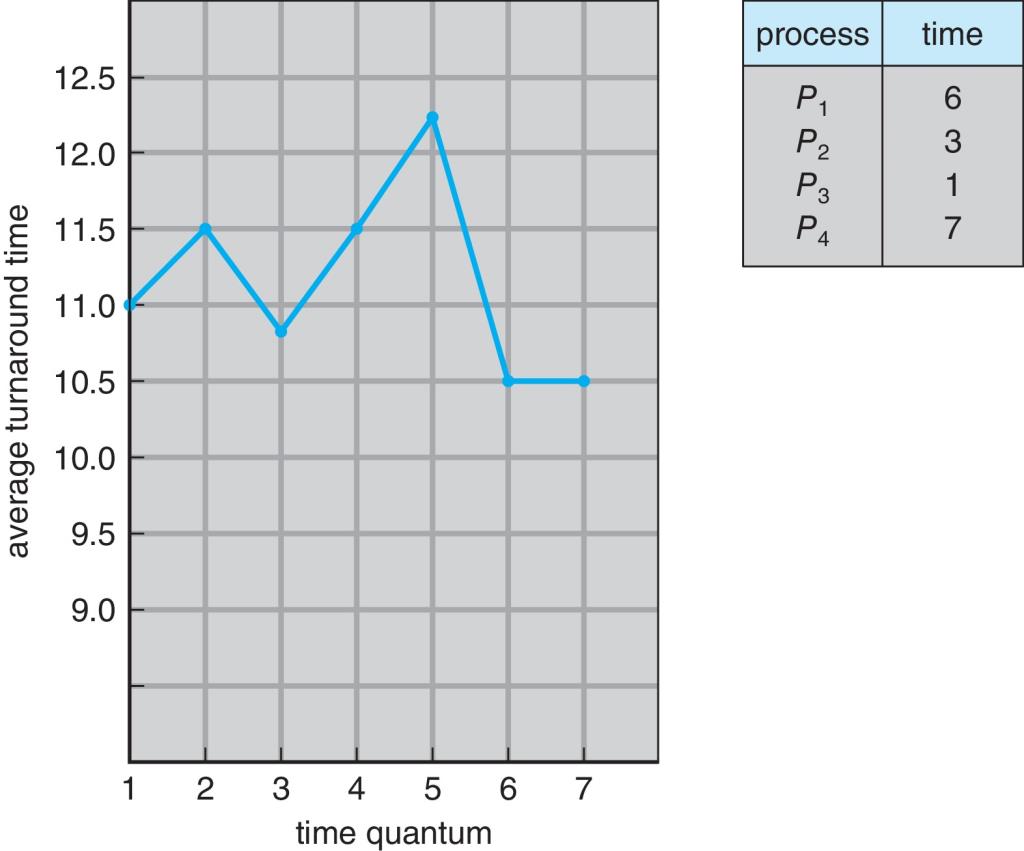
$q=6$, Average turnaround time = $(6+9+10+17)/4 = 10.5$
$q=7$, Average turnaround time = $(6+9+10+17)/4 = 10.5$
Priority Scheduling
-
A priority number (integer) may be associated with each process
-
The CPU is allocated to the process with the highest priority
- (smallest integer = highest priority)
-
Two policies
- Preemptive
- the current process is pre-empted immediately by high priority process
- Non-preemptive
- the current process finishes its burst first, then scheduler chooses the process with highest priority
- Preemptive
-
SJF is priority scheduling where priority is the inverse of predicted next CPU burst time
-
Problem
- (考点) Starvation: low priority processes may never execute
-
Solution
- (考点) Aging: as time progresses increase the priority of the process
Example of Priority Scheduling
smallest integer = highest priority
| Process | Burst Time | Priority |
|---|---|---|
| $P_1$ | 10 | 3 |
| $P_2$ | 1 | 1 |
| $P_3$ | 2 | 4 |
| $P_4$ | 1 | 5 |
| $P_5$ | 5 | 2 |
- Priority scheduling (not preemptive) Gantt Chart

- Average waiting time = $(6+0+16+18+1)/5 = 8.2$
Priority Scheduling w/ Round-Robin
| Process | Burst Time | Priority |
|---|---|---|
| $P_1$ | 4 | 3 |
| $P_2$ | 5 | 2 |
| $P_3$ | 8 | 2 |
| $P_4$ | 7 | 1 |
| $P_5$ | 3 | 3 |
- Run the process with the highest priority. Processes with the same priority run round-robin

Multilevel Queue
- Ready queue is partitioned into separate queues, e.g.:
- foreground (interactive 交互processes)
- background (batch 批处理 processes)
- Process permanently in a given queue (stay in that queue)
- Each queue has its own scheduling algorithm:
- foreground – RR
- background – FCFS
- Scheduling must be done between the queues:
- Fixed priority scheduling
- Each queue has a given priority
- High priority queue is served before low priority queue
- Possibility of starvation
- Time slice
- each queue gets a certain amount of CPU time
- Each queue has a given priority
- Fixed priority scheduling
- With priority scheduling, for each priority, there is a separate queue
- Schedule the process in the highest-priority queue!
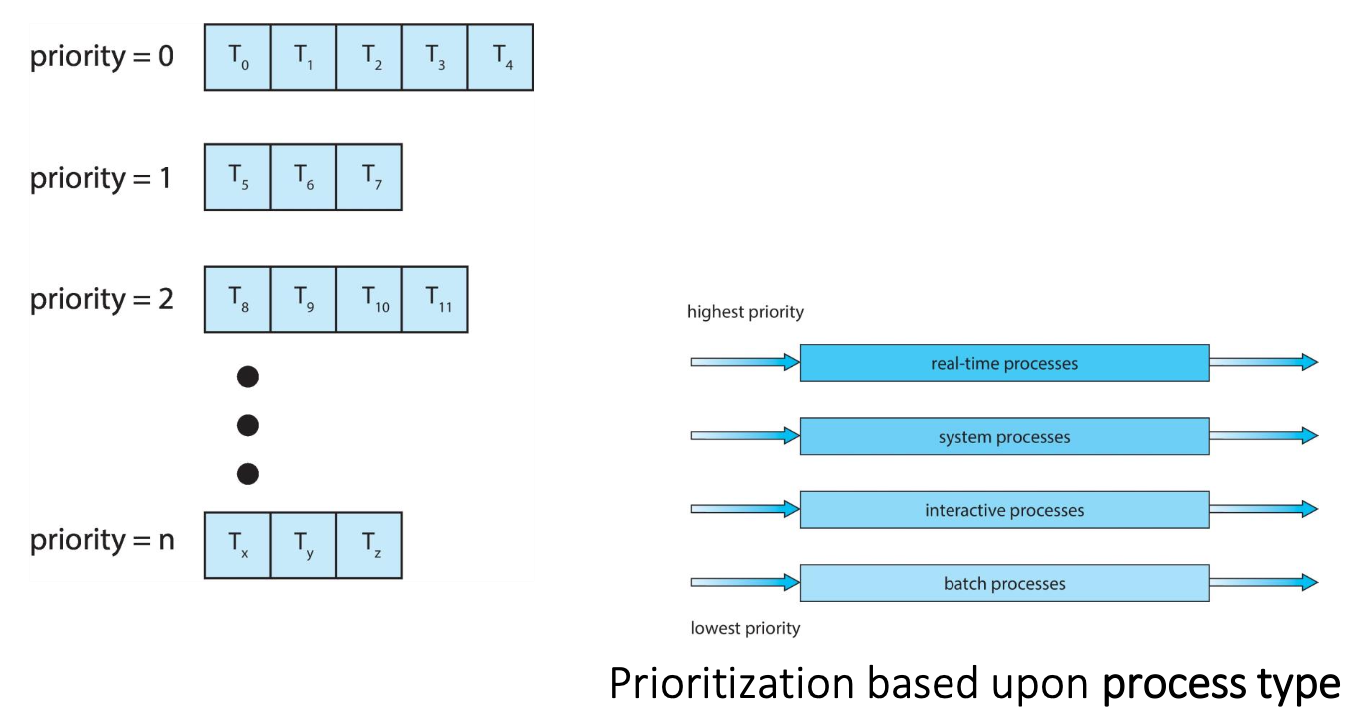
Multilevel Feedback Queue
- A process can move between the various queues;
- aging can be considered in this way (prevent starvation)
- Advantage: prevent starvation
- The multilevel feedback queue scheduler
- the most general CPU scheduling algorithm
- defined by the following parameters:
- number of queues
- scheduling algorithms for each queue
- Policies on moving process between queues
- when to upgrade a process
- when to demote (降级) a process
- which queue a process will enter when that process needs service
Example of Multilevel Feedback Queue
- Three queues:
- $Q_0$ – RR with time quantum 8 milliseconds
- $Q_1$ – RR with time quantum 16 milliseconds
- $Q_2$ – FCFS
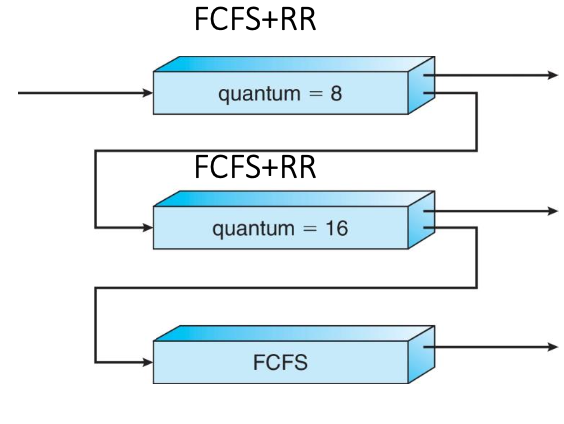
- Scheduling
-
A new job enters queue $Q_0$ which is served FCFS
- When it gains CPU, job receives 8 milliseconds
- If it does not finish in 8 milliseconds, job is moved to queue $Q_1$
-
At $Q_1$ job is again served FCFS and receives 16 additional milliseconds
- If it still does not complete, it is preempted and moved to queue $Q_2$ where it runs until completion but with a low priority
-
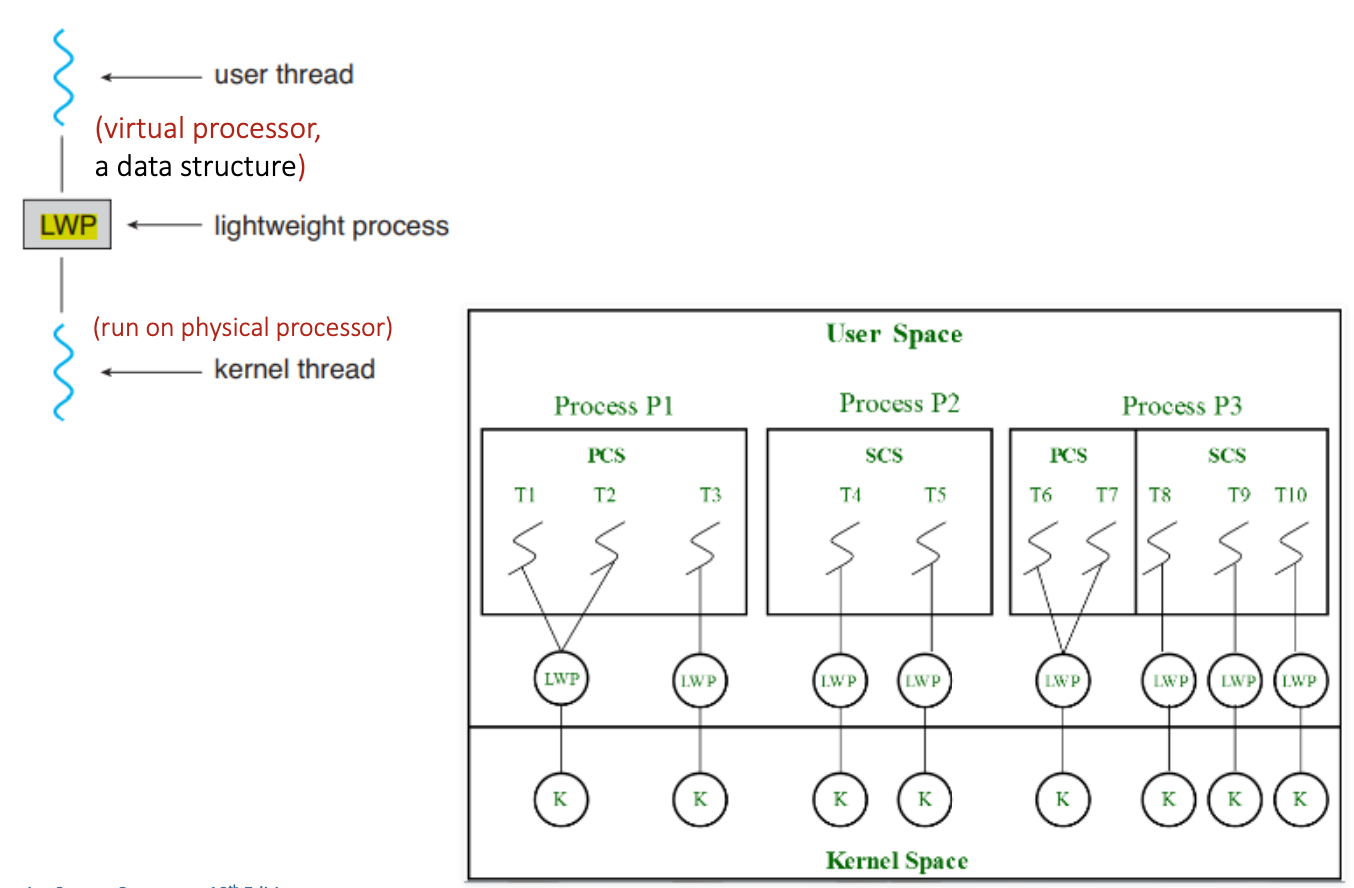
Thread Scheduling
- Distinguish between user-level and kernel-level threads
- When threads are supported by kernel,
- threads are scheduled, not processes
- Many-to-one and many-to-many models,
- thread library schedules user-level threads to run on kernel threads (LWP: light-weight process)
- process-contention scope (PCS)
- competition is between user-level threads within the same process
- Typically priority is set by programmer
- thread library schedules user-level threads to run on kernel threads (LWP: light-weight process)
- Kernel threads are scheduled by Kernel onto available CPU
- system-contention scope (SCS)
- competition is among all kernel-level threads from all processes in the system
Multi-Processor Scheduling
- CPU scheduling is more complex when multiple CPUs are available
- Traditionally, Multiprocessor means multiple processors
- The term Multiprocessor now applies to the following system architectures:
- Multicore CPUs
- Multithreaded cores
- NUMA systems
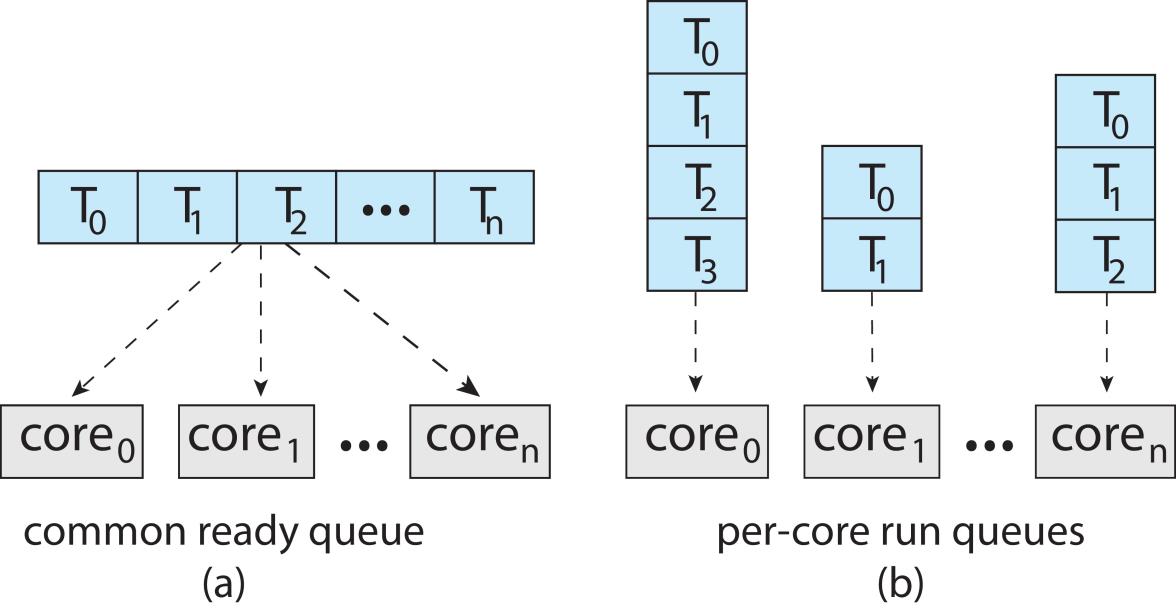
- Symmetric multiprocessing (SMP) is where each processor is self scheduling
- Two possible strategies
- All threads may be in a common ready queue (a)
- Each processor may have its own private queue of threads (b)
- Two possible strategies
Multicore Processors
-
Recent trend: multiple processor cores are on same physical chip
- Faster and consumes less power
-
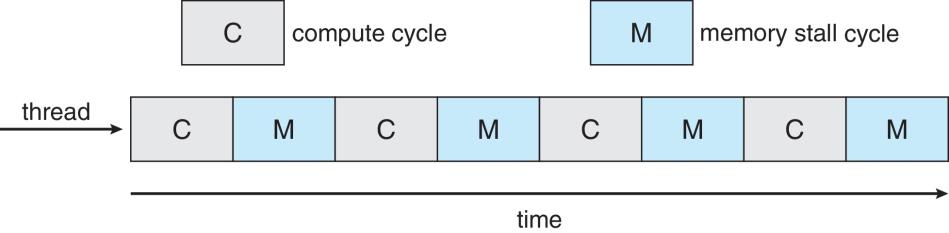
Multiple threads per core also growing
- memory stall (延迟) : An event that occurs when a thread is on CPU and accesses memory content that is not in the CPU’s cache. The thread’s execution stalls while the memory content is retrieved and fetched
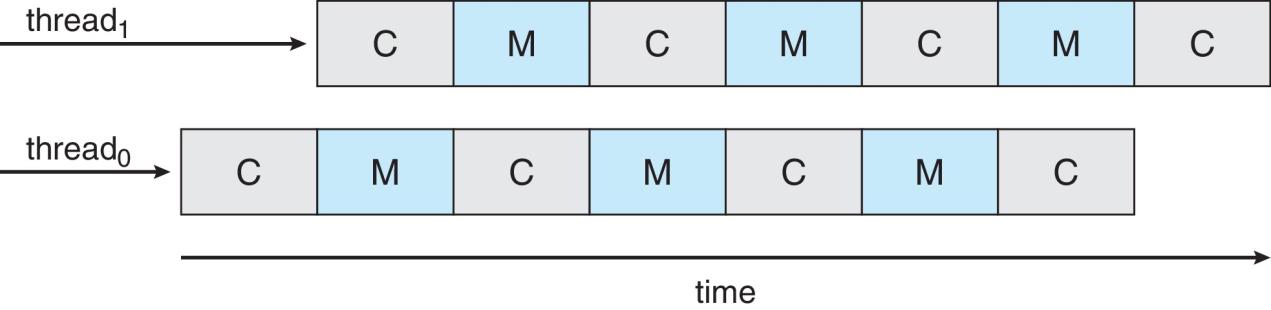
- Solution:
- Each core has more than one hardware threads. If one thread has a memory stall, switch to another thread!
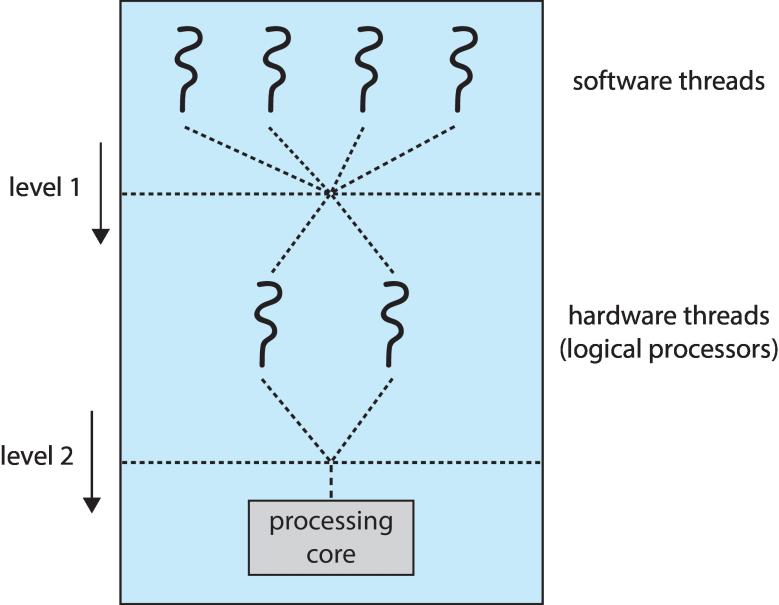
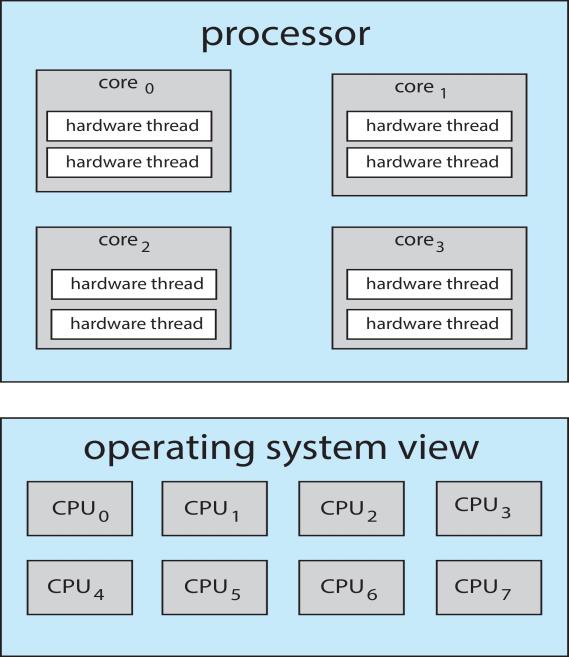
Multithreaded Multicore System
- Chip-multithreading (CMT) assigns each core multiple hardware threads. (Intel refers to this as hyperthreading.)
- On a quad-core system (4核) with 2 hardware threads per core, the operating system sees 8 logical processors.
- Two levels of scheduling:
- The operating system deciding which software thread to run on a logical CPU
- Each core decides which hardware thread to run on the physical core.
 |
 |
|---|
Multiple-Processor Scheduling – Load Balancing
- If SMP, need to keep all CPUs loaded for efficiency
- Load balancing attempts to keep workload evenly distributed
- Push migration – periodic task checks load on each processor, and pushes tasks from overloaded CPU to other less loaded CPUs
- Pull migration – idle CPUs pulls waiting tasks from busy CPU
- Push and pull migration need not be mutually exclusive
- They are often implemented in parallel on load-balancing systems.
Multiple-Processor Scheduling – Processor Affinity
- Processor affinity
- When a thread has been running on one processor, the cache contents of that processor stores the memory accesses by that thread, i.e., a thread has affinity for a processor
- Load balancing may affect processor affinity
- a thread may be moved from one processor to another to balance loads,
- that thread loses the contents of what it had in the cache of the processor it was moved off
- Soft affinity – the operating system attempts to keep a thread running on the same processor, but no guarantees.
- Hard affinity – allows a process to specify a set of processors it may run on.
- The kernel then never moves the process to other CPUs, even if the current CPUs have high loads.
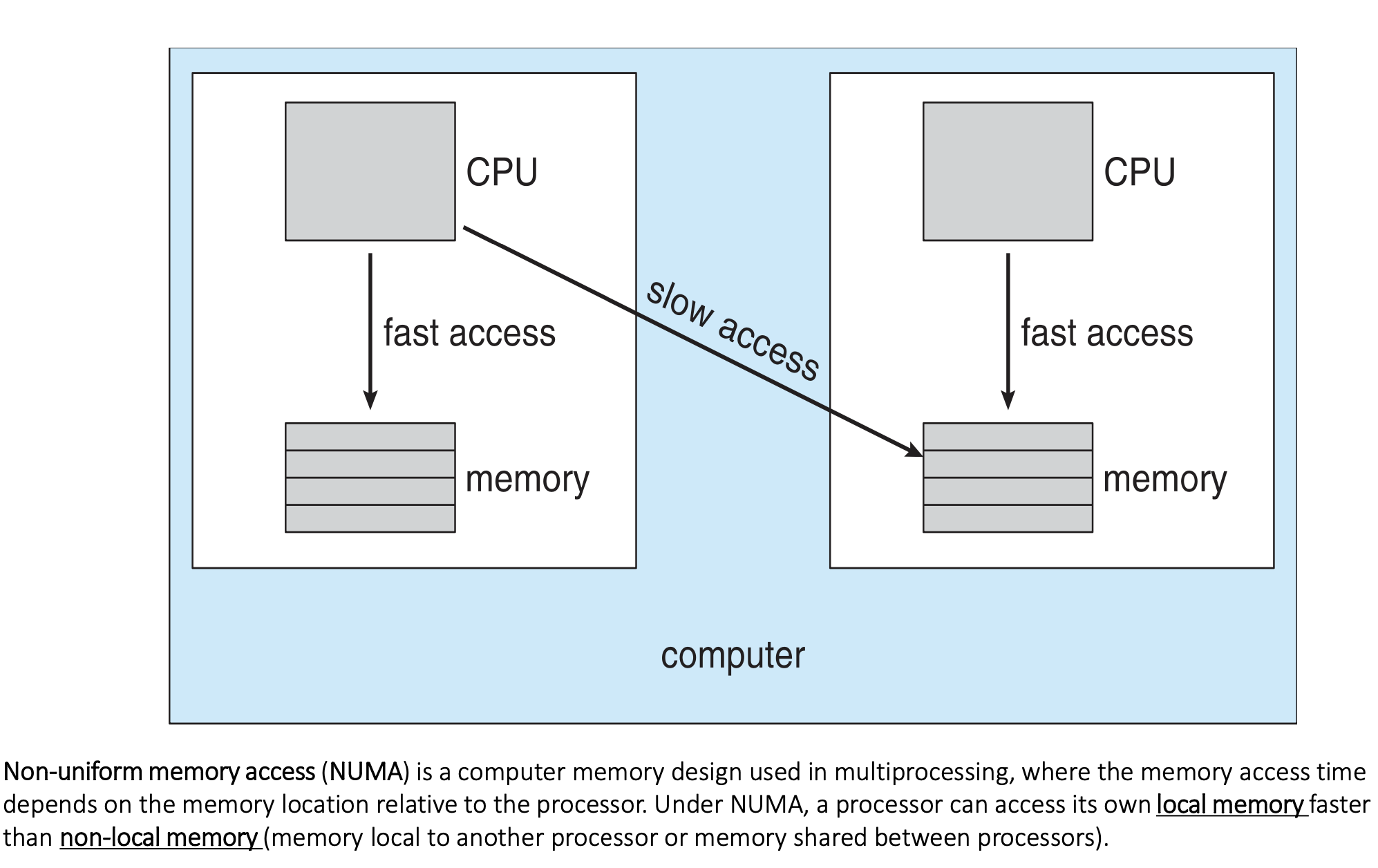
NUMA and CPU Scheduling
- If the operating system is NUMA-aware, it will assign memory closest to the CPU the thread is running on.
Real-Time CPU Scheduling
- Real-time CPU scheduling presents obvious challenges
- Soft real-time systems
- Critical real-time tasks have the highest priority, but no guarantee as to when tasks will be scheduled (best try only)
- Hard real-time systems
- a task must be serviced by its deadline (guarantee)
- Soft real-time systems
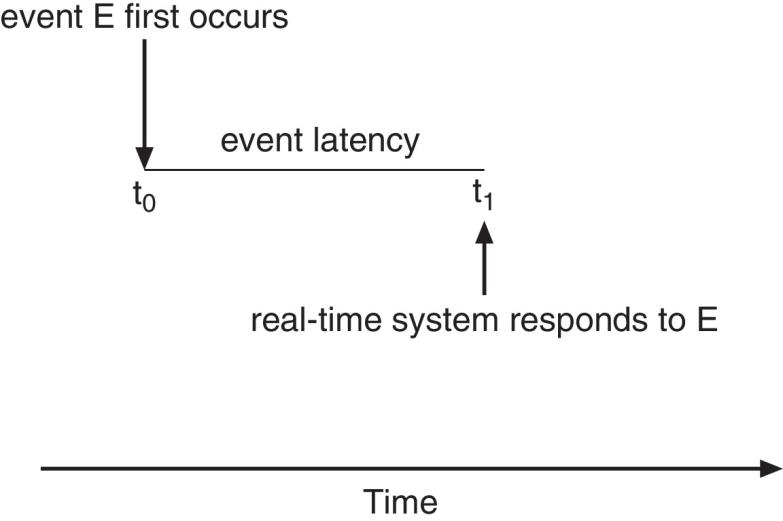
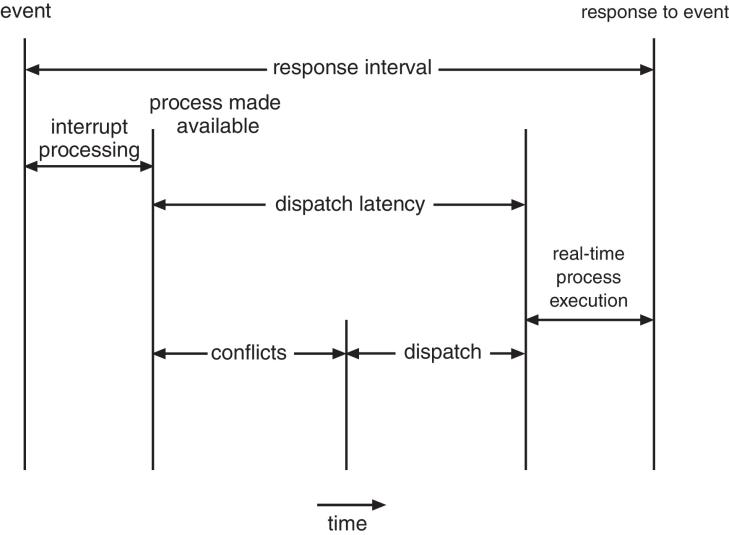
- Event latency – the amount of time that elapses from when an event occurs to when it is serviced.
- Two types of latencies affect performance
- Interrupt latency – time from arrival of interrupt to start of kernel interrupt service routine (ISR) that services interrupt
- Dispatch latency(调度延迟) – time for scheduler to take current process off CPU and switch to another
 |
 |
|---|
Priority-based Scheduling
- For real-time scheduling, scheduler must support preemptive, priority-based scheduling
- But only guarantees soft real-time
- For hard real-time, must also provide ability to meet deadlines
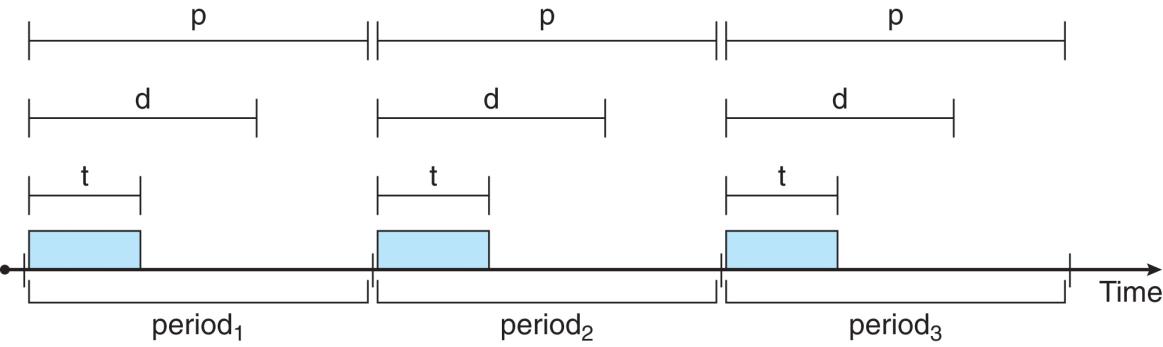
- Processes have new characteristics: periodically require CPU at constant intervals
- Has processing time t, deadline d, period p
- 0≤t≤d≤p
- *Rate of periodic task is 1/*p
Rate Monotonic Scheduling
- A priority is assigned based on the inverse of its period
- Shorter periods = higher priority
- Longer periods = lower priority
- In the following example, P1 is assigned a higher priority than P2.
- P1 needs to run for 20 ms every 50 ms. t = 20, d = p = 50
- P2 needs to run for 35 ms every 100 ms. t = 35, d = p = 100
- Assume deadline d = p

Missed Deadlines with Rate Monotonic Scheduling
- Example:
- P1 needs to run for 25 ms every 50 ms. t = 25, d = p = 50
- P2 needs to run for 35 ms every 80 ms. t = 35, d = p = 80

- Process P2 misses its deadline at time 80 ms.
- Observation: if P2 is allowed to run from 25 to 60 and P1 then runs from 60 to 85 then both processes can meet their deadline.
- So the problem is not a lack of CPU time, the problem is that rate monotonic scheduling is not a very good algorithm.
Earliest Deadline First Scheduling (EDF)
- Priorities are assigned according to deadlines:
- the earlier the deadline, the higher the priority;
- the later the deadline, the lower the priority.

- Example:
- P1 needs to run for 25 ms every 50 ms.
- P2 needs to run for 35 ms every 80 ms.
- This is the scheduling algorithm many students use when they have multiple deadlines for different homework assignments!
Proportional Share Scheduling
- T shares are allocated among all processes in the system
- Example: T = 20, therefore there are 20 shares, where one share represents 5% of the CPU time
- An application receives N shares where N < T
- This ensures each application will receive N / T of the total processor time
- Example: an application receives N = 5 shares
- the application then has 5 / 20 = 25% of the CPU time.
- This percentage of CPU time is available to the application whether the application uses it or not.
POSIX Real-Time Scheduling API
#include <pthread.h>
#include <stdio.h>
#define NUM_THREADS 5
int main(int argc, char *argv[])
{
int i, policy;
pthread_t_tid[NUM_THREADS];
pthread_attr_t attr;
/* get the default attributes */
pthread_attr_init(&attr);
/* get the current scheduling policy */
if (pthread_attr_getschedpolicy(&attr, &policy) != 0)
fprintf(stderr, "Unable to get policy.\n");
else
{
if (policy == SCHED_OTHER)
printf("SCHED_OTHER\n");
else if (policy == SCHED_RR)
printf("SCHED_RR\n");
else if (policy == SCHED_FIFO)
printf("SCHED_FIFO\n");
}
/* set the scheduling policy - FIFO, RR, or OTHER */
if (pthread_attr_setschedpolicy(&attr, SCHED_FIFO) != 0)
fprintf(stderr, "Unable to set policy.\n");
/* create the threads */
for (i = 0; i < NUM_THREADS; i++)
pthread_create(&tid[i], &attr, runner, NULL);
/* now join on each thread */
for (i = 0; i < NUM_THREADS; i++)
pthread_join(tid[i], NULL);
}
/* Each thread will begin control in this function */
void *runner(void *param)
{
/* do some work ... */
printf("my thread ID=%u\n", *(unsigned int *)param);
pthread_exit(0);
}
Operating Systems Examples
Linux Scheduling
-
Scheduling classes
- 2 scheduling classes are included, others can be added
- default
- real-time
- Each process/task has specific priority
- 2 scheduling classes are included, others can be added
-
Real-time scheduling according to POSIX.1b
- Real-time tasks have static priorities
-
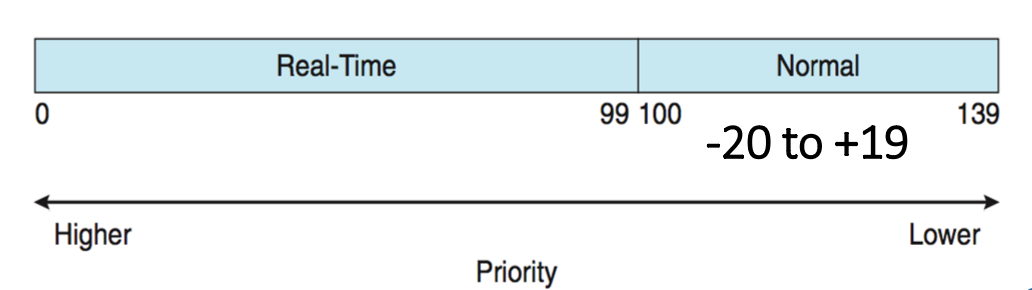
Real-time plus normal tasks map into global priority scheme
- Nice value of -20 maps to global priority 100
- Nice value of +19 maps to priority 139
- Completely Fair Scheduler (CFS)
- Scheduler picks highest priority task in highest scheduling class
- Quantum is not fixed
- Calculated based on nice value from -20 to +19
- Lower value is higher priority
- Scheduler picks highest priority task in highest scheduling class
- CFS maintains per task virtual run time in variable vruntime
- Associated with decay factor based on priority of task => lower priority is higher decay rate
- Normal default priority (Nice value: 0) yields virtual run time = actual run time
- To decide next task to run, scheduler picks task with lowest virtual run time
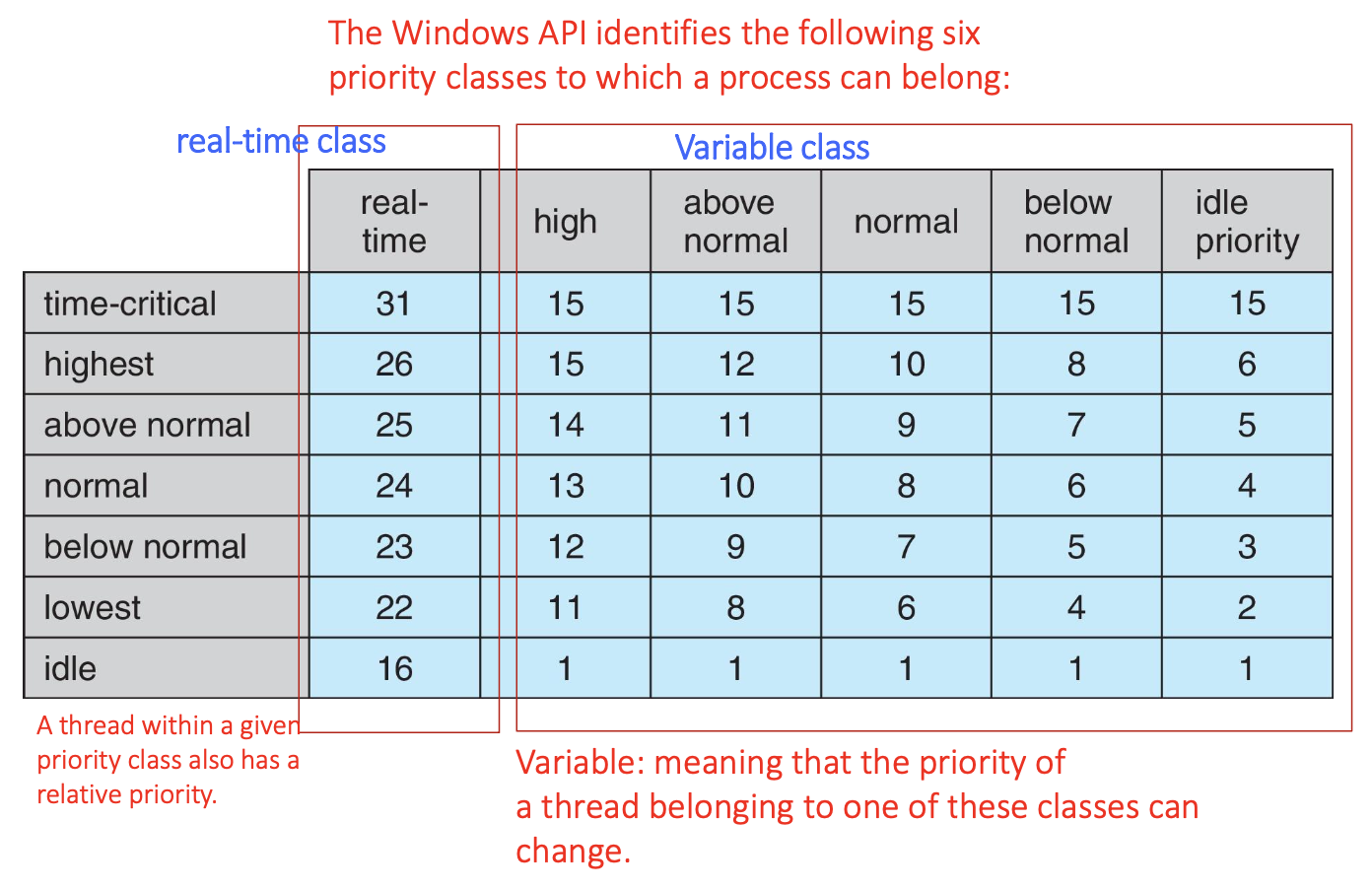
Windows scheduling
- Windows uses priority-based preemptive scheduling
- Highest-priority thread runs next
- Thread runs until
- blocks
- uses time slice
- preempted by higher-priority thread
- Thread runs until
- Highest-priority thread runs next
- Real-time threads can preempt non-real-time
- 32-level priority scheme
- Variable class is 1-15, real-time class is 16-31
- Priority 0 is memory-management thread
- There is a queue for each priority
- If no run-able thread, runs idle thread
Windows Priorities